
My DevLog
[cs231n] Lecture 3 | Loss Functions and Optimization 내용 정리 본문
[cs231n] Lecture 3 | Loss Functions and Optimization 내용 정리
므느르으 2021. 4. 3. 14:00📚 Stanford cs231n
Loss Functions and Optimization
✅ TODO
✔ Define a loss function that quantifies our unhappiness with the scores across the training data
✔ Come up with a way of efficiently find the parameters that minimize the loss function(optimization)
W가 좋은지 안 좋은지 정량화 해주는 것이 바로 Loss function 이다. 그리고 이를 좋은 쪽으로 발전시키는 것을 Optimization이라 한다.

예제를 단순화 시켜 3개의 class 만 있다고 가정하자.
세 이미지에 대한 W 값을 보면 자동차 이미지만 정답을 맞추고 있다. 이는 Linear classifier가 잘 작동하고 있지 않다는 의미이다.
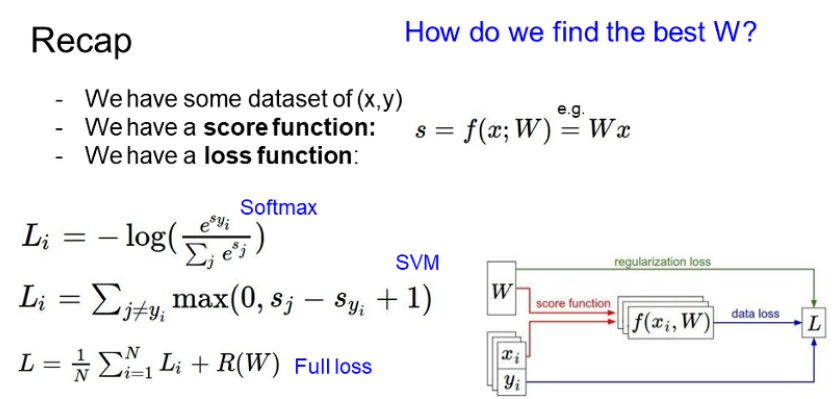
Multiclass SVM loss

- SVM loss의 작동 원리
- 카테고리를 보고 정답 카테고리라면 넘어간다.
- 정답 카테고리가 아닌 경우 현재 카테고리의 점수 - 정답 점수 + 1 을 계산하여 0보다 크다면 loss 값에 더한다.
- 0보다 작을 경우 loss 값은 0

❓ 점수가 낮으면 좋은 것인가?
👉 맞다. 구하는 것이 결국 정답과의 차이가 얼마나 큰지 나타내는 값이므로 이 점수가 낮으면 정답과 비슷하다는 의미이다.
❓ 자동차의 score을 조금 바꾼다면?
👉 이미 다른 class와의 격차가 있으므로 영향 없음. 즉, 데이터의 변화에 둔감하다고 해석 가능하다. score의 숫자 그 자체보다는 정답 클래스와 다른 클래스간의 차이가 중요하다.
❓ 최솟값 / 최댓값은?
👉 최소는 0, 최대는 무한대
❓ 정답 클래스를 제외하지 않고 계산하면?
👉 평균 값이 1 증가한다. 이렇게 되면 loss의 최솟값이 1이 되므로 정답 클래스를 제외하여 최솟값이 0이 되도록 한다.
❓ Loss 값이 0인 W는 유일한가?
👉 아니다! W의 loss가 0이라면 2W 역시 0의 loss를 갖는다.
Regularization
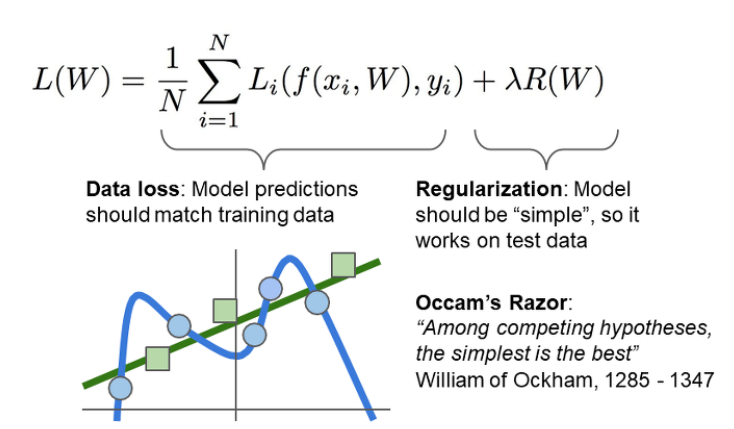
지금까지 한것은 training set에 대해 W 값을 맞춰준 것이다. 그러나 우리가 궁극적으로 원하는 것은 test set에도 작용하도록 하는 것! 이때 training set에 overfitting 된는 것을 막아줄 수 있는게 Regularization이다. 아래와 같이 여러 종류의 Regularization이 있다.

Softmax Classifier

- Softmax의 작동 원리
- 각 클래스마다 score를 구하고 exp를 곱한다.
- 이 수들을 normalization해서 확률로 만들어준다. 즉 전부 더하면 1이 되도록 한다.
- 이 값에 -log를 씌운다. 확률이 0에 가까운 경우 loss가 무한대로 가고, 확률이 1에 가까울수록 loss가 0에 가까워진다.
❓ 최솟값 / 최댓값은?
👉 이론적으로는 최솟값이 0, 최댓값은 무한대지만 실제로는 나올 가능성 거의 없다.
❓ 데이터의 score를 조금 바꾼다면?
👉 확률로 계산하기 때문에 데이터의 변화에 민감하게 반응한다(SVM과 대비됨)
Optimization
- Random Search
말 그대로 랜덤하게 찾는 방법. 별로임! 실제로 쓰지 말아라 - Follow the slope : Gradient Descent
- Numerical Method
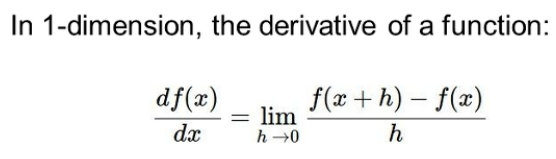
하나하나 차이를 구하는 방법
굉장히 비효율적임! - Analytic Gradient
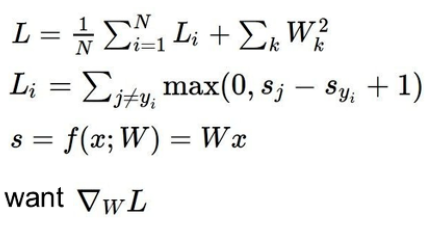
미분을 써서 한번에 구하자! 정확하고 빠르지만 에러 나올 가능성 높음.
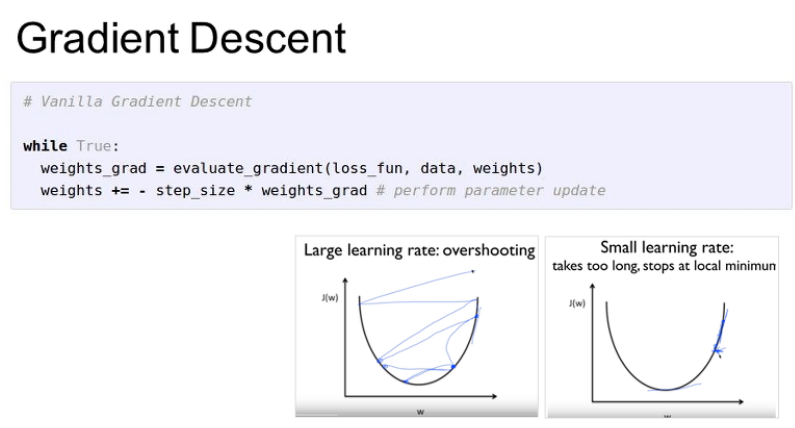
앞에 -를 붙여서 음의 기울기를 갖는다면 +방향, 양의 기울기를 갖는다면 -방향으로 가도록 한다.
올바른 Step size(Learning rate)를 찾는 것이 중요하다. 기울기가 0인 지점에 가장 빠르게 도달할 수 있도록 하는 것이 목표.
adam optimizer, rms prop 등 다양한 방법을 배울 것이다!
Stochastic Gradient Descent(SGD)

지금까지는 모든 N을 한번에 계산했다.
이는 N이 굉장히 커질 경우 매우 비효율적이고 느린 방식이다. W가 한번 업데이트 되려면 처음부터 끝까지 계산해야하기 때문이다.
--> 이떄 사용하는 것이 SGD이다.
minibatch를 설정하여 데이터를 보통 32, 64, 128 등의 숫자로 잘라서 사용한다.
❗ Image Features
이전까지는 이미지 전체를 그냥 사용했다면, 특징들을 뽑아내고 이를 linear regression에 이용하는 방식이 사용되었다.
- Color Histogram
어떤 color가 많이 나오는지 count를 세어 특징을 추출하는 방식. - Histogram of Oriented Gradients(HoG)
방향 값을 히스토그램으로 나타내어 특징 추출 - Bag of Words
자연어처리에서 많이 사용되는 방식
현재는 입력한 이미지에서 스스로 특징을 뽑아내도록 하는 CNN이 주로 사용됨
'Deep Learning > Stanford c231n' 카테고리의 다른 글
| [cs231n] CNN Architectures 내용 정리 (0) | 2021.06.27 |
|---|---|
| [cs231n] Training Neural Networks I 내용 정리 (0) | 2021.06.27 |
| [cs231n] Convolutional Neural Networks 내용 정리 (0) | 2021.06.27 |
| [cs231n] Introduction to Neural Networks 내용 정리 (0) | 2021.06.27 |
| [cs231n] Lecture 1 | Introduction to CNN for Visual Recognition 내용 정리 (0) | 2021.03.21 |